Algorithms
教材への理解を深めるために、理解しておくと良いアルゴリズムについて紹介します。興味を惹かれる論文があれば、Sample NodeのDesignを参考にして、ROS Nodeを作成してみてください。
前提知識
- 機械学習、深層学習の知識
- MLP, CNN, Transformer等の用語について理解している方を対象とします。
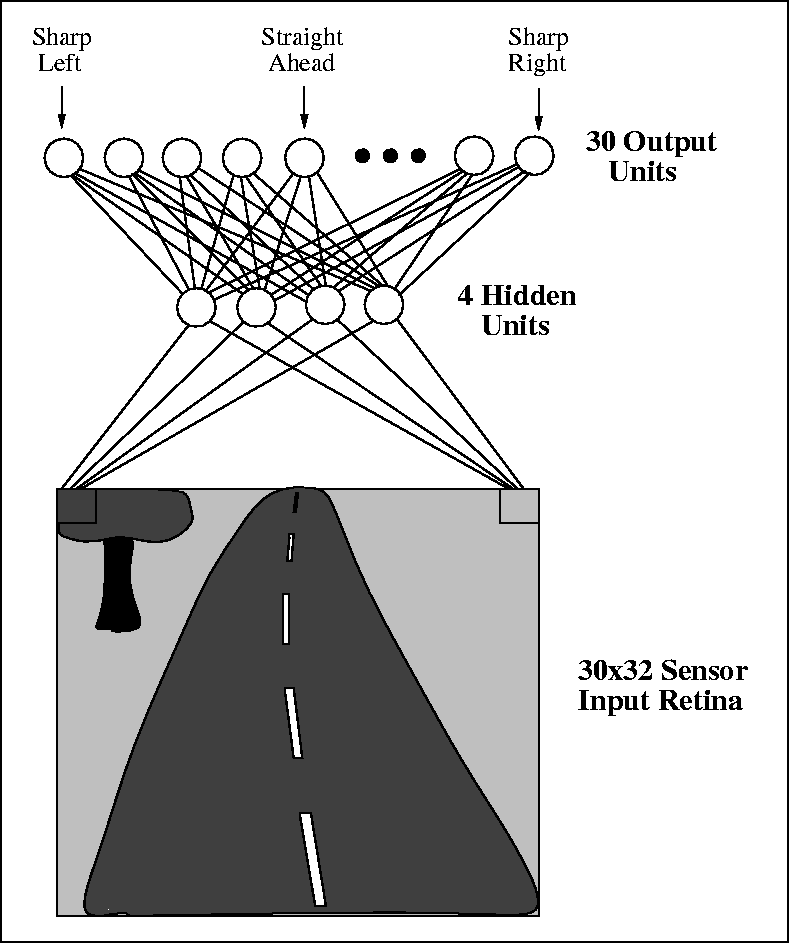
ALVINN
- 1980年代に発表された、深層学習による自動運転手法です。
- 当時の計算能力は非常に限られていたため、たった3層の全結合型Neural Networkが使われていました。
- 論文: An Autonomous Land Vehicle In a Neural Network
引用元: https://jmvidal.cse.sc.edu/talks/ann/alvinn2.gif
DAVE-2
- 2016年にNVIDIAから発表された手法で、CNNを用いています。
- ALVINNよりも計算機が強力になったものの、5層のconvolution layerと3層の全結合層からなる、コンパクトな構成でした。
- 論文: End to End Learning for Self-Driving Cars

引用元: https://figures.semanticscholar.org/0e3cc46583217ec81e87045a4f9ae3478a008227/3-Figure2-1.png
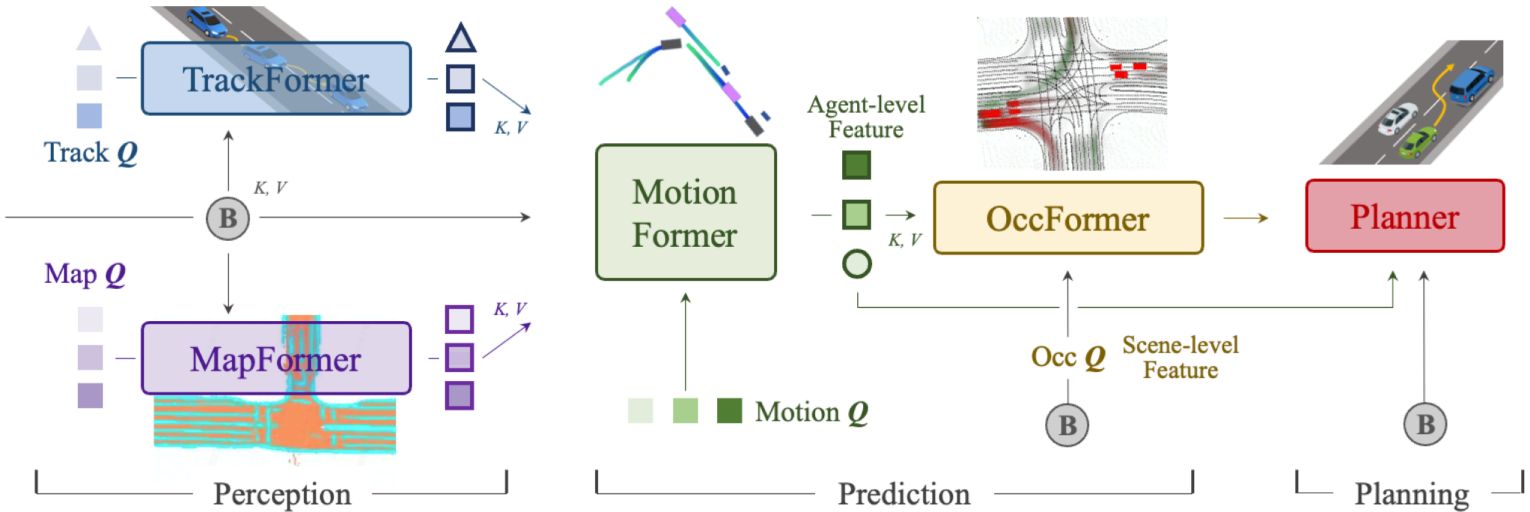
UniAD
- CVPR2023でOpenDriveLabから発表された手法で、画像を入力とし、trajectory(waypoints)を出力します。現在幅広く使われている、センサが入力、trajectoryが出力となる自動運転手法の基礎となっています。
- "Query based"と呼ばれる方法で、各module間をつなぐ手法を採用。
- 複数の画像を、BEVFormerと呼ばれる手法で処理し、BEV特徴量(Bird-eye-view, 鳥瞰図のように交通環境を上から見たときの特徴量)を取得します。
- Map情報はRasterで表現しており、かなり推論が遅いです(A100で1~4 FPS)
- 論文: Planning-oriented Autonomous Driving
- code
引用元: https://opendrivelab.com/assets/publication/uniad.jpg

引用元: https://github.com/OpenDriveLab/UniAD/blob/v2.0/sources/cvpr23_uniad_poster.png?raw=true
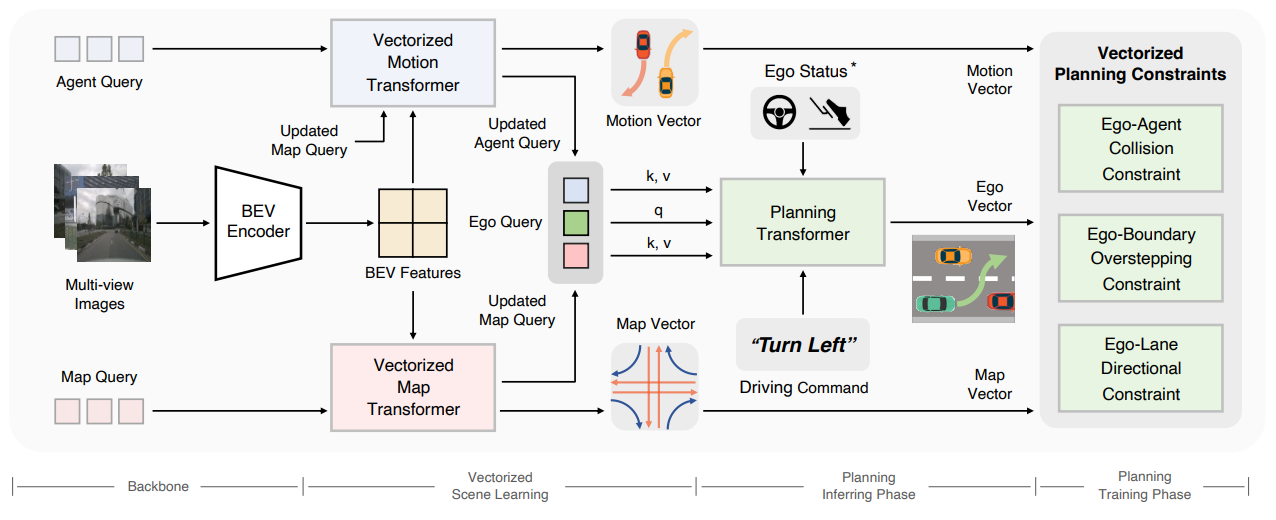
VAD
- ICCV2023で発表された手法です。
- BEV特徴量の使用、"Query based"な思想をUniADから引き継ぎながらも、Raster mapではなくVector mapを使用することで高速化・軽量化を達成。RTX3090で16.8 Fpsで動きます。
- 論文: VAD: Vectorized Scene Representation for Efficient Autonomous Driving
- code
引用元: https://raw.githubusercontent.com/hustvl/VAD/main/assets/arch.png
Sample ROS NodeではVAD-tinyと呼ばれるmodelを使用しています。
TinyLiDARNet
- F1TENTHにて使用された手法です。
- 2D LiDARのデータから、速度とステアリング角を推定します。
- input: 長さ
1081の1次元配列。2D LiDARで得られたxy平面上の距離を格納。 - output: Speed, Steering Angle
- input: 長さ
- 5層のconvolution, 4層のFully-connectedから構成されており、非常にシンプルなモデルです。そのため、1万sampleを使った学習がNVIDIA Jetson Xavier NXにて4分で終了し、int8量子化したmodelがESP32-S3にて16msで動くなど、かなり軽量です。
-
static obstacleしか含んでいないデータセットで学習させたにも関わらず、他の車のovertakeを実行できたり、実データで学習したモデルをシミュレータ上で評価しても(Real2Sim)高い走破性を誇る(論文 Table. Ⅱ)など、性能も安定しています。
-
論文: TinyLidarNet: 2D LiDAR-based End-to-End Deep Learning Model for F1TENTH Autonomous Racing
- code

引用元: https://github.com/CSL-KU/TinyLidarNet
VLM based planner
- 言語モデルを使用したPlannerも多数登場しています。いくつか例を紹介します。
EMMA
- Geminiを自動運転データでfine-tuningして使用しています。
- 道路上にカバンやハシゴが落ちていたら避ける軌道を出力し、路上にリスがいたらslow downするなど、long-tail driving scenario(珍しいシナリオ)に対応できるとの結果が得られています。
- 論文: EMMA: End-to-End Multimodal Model for Autonomous Driving
OmniDrive
- NVIDIAがCVPR2025で発表した論文です。
- 「もしこの状況でこうするとどうなりますか?」というcounterfactual reasoning(反実仮想)の訓練ができるようなdatasetを作成しています。
- 論文: OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning
- code

引用元: https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202025/34693.png?t=1748858551.4455686
S4-Driver
- WaymoがCVPR2025で発表した論文です。
- 「VLMが2次元画像でしか事前学習しておらず、Motion Planningでの性能が低い」という課題感から、UniAD, VADのようなBEV特徴量を使った手法から着想を得て、BEV特徴量を使用したVLM modelを提案しています。
- 論文: S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Modelwith Spatio-Temporal Visual Representation

引用元: https://cvpr.thecvf.com/media/PosterPDFs/CVPR%202025/32619.png?t=1748995327.7679746
VLM + BEVのhybrid planner
- UniAD, VADのようなBEV特徴量を用いたPlannerと、VLMとを統合したPlannerも提案されています。
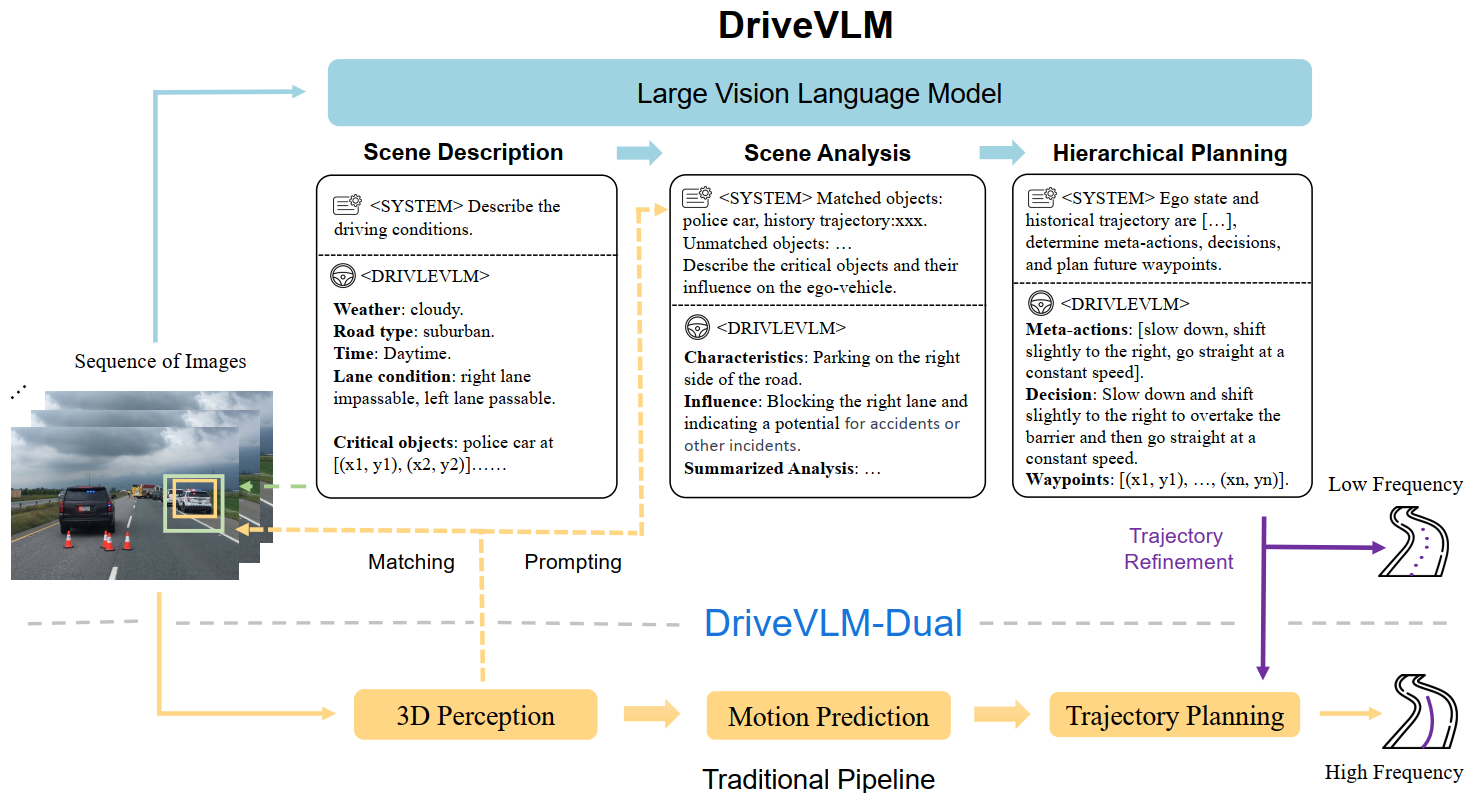
DriveVLM
"Fast&Slow"と呼ばれる、「VLMによる遅い推論」と「VADのようなmodelによる速い推論」を組み合わせたmodelです。- 「草木が落ちているような状況で回避軌道を生成できる」「警察の手でのジェスチャーに対応した軌道を生成できる」といった、long-tail driving scenario(珍しいシナリオ)に対応できるとの結果が得られています。
- 論文: DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
- youtube link
引用元: https://tsinghua-mars-lab.github.io/DriveVLM/images/pipeline.png
Senna
- VLMと学習ベースのPlannerを結合した手法です。
- VLMでhigh levelなcommandを決定し、VADのようなBEV特徴量を用いたmodelで使用します。
- 論文: Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
- code

引用元: https://github.com/hustvl/Senna/raw/main/assets/teaser.png